系统架构
GEA 的三大核心组件:Archive → Parent Group Selection → Group Evolution
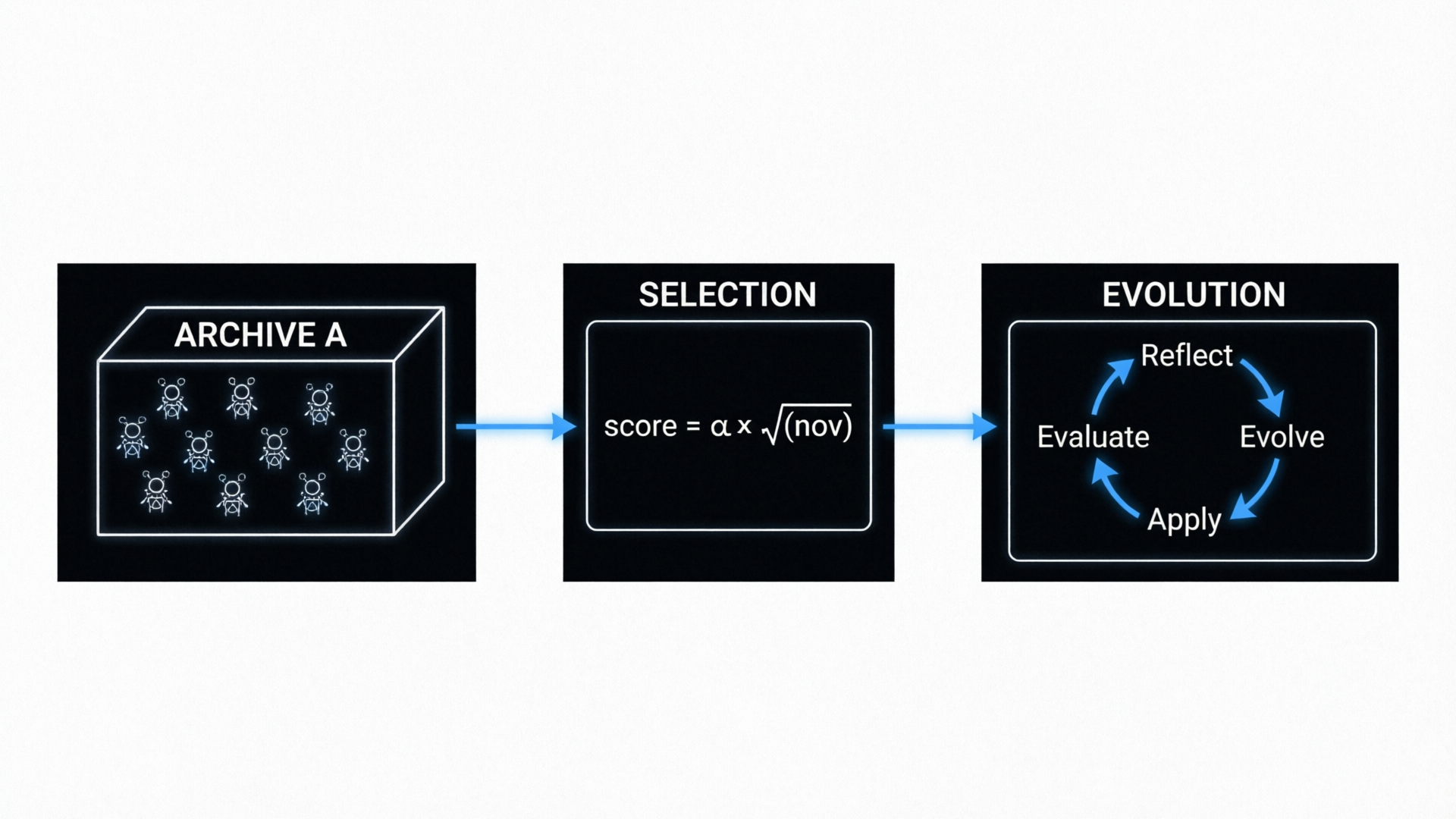
Archive(档案库)
符号:𝒜。存储进化过程中发现的所有智能体。每个智能体 i 用任务成功向量 \(z_i \in \{0,1\}^D\) 表示,并关联性能分数 \(\alpha_i\)。其中 D 是探测任务集合的大小,每个维度表示智能体是否成功解决对应的探测任务。
基于经验共享的开放式自我改进。SWE-bench 71.0%,Polyglot 88.3%。零额外推理成本匹配人工工程化系统。
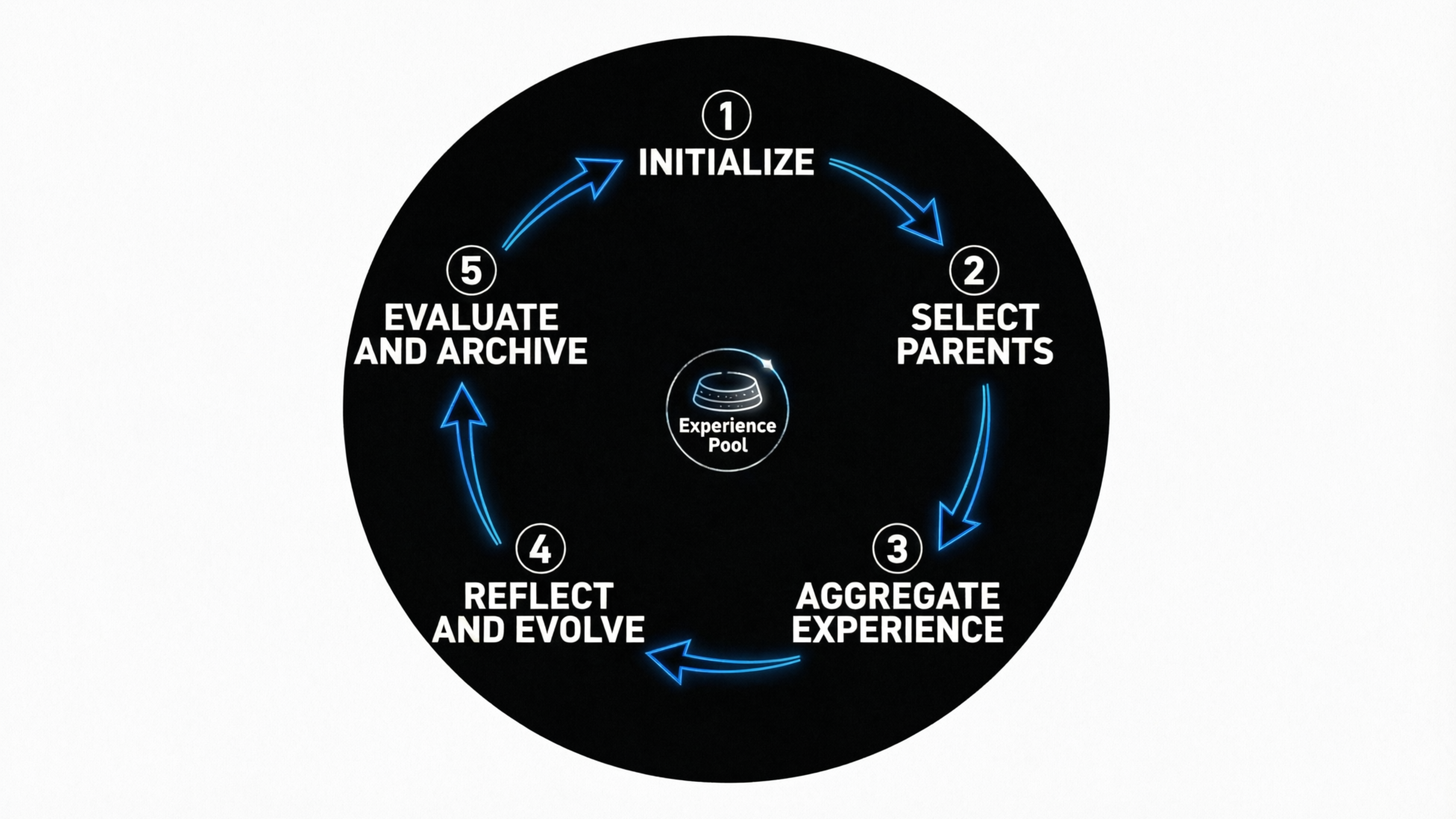
群体进化智能体(GEA)提出了一种全新的 AI 系统开放式自我改进范式。与当前主流框架中将单个智能体作为进化单元的"孤狼"式方法不同,GEA 将一组智能体作为基本的进化单位。组内智能体可以自主修改自身结构设计以提升能力并克服局限。共享的经验池被每一个未来的智能体作为既定事实继承,从而实现了初始探索的多样性并随时间不断演化。
在具有挑战性的编码基准测试中,GEA 达到 71.0%(SWE-bench Verified),而此前自我进化方法仅为 56.7%;在 Polyglot 上达到 88.3% vs 68.3%。GEA 以零额外推理成本匹配了人工工程化的 AI 系统(71.0% vs 71.8% OpenHands+GPT-5)。
进化作用于群体层面而非个体。每次迭代选择 K 个父代智能体组成群体,共同产生同等大小的子代群体。超参数:K=2,M=4。
父代群体中每个智能体的进化轨迹(代码补丁、失败任务、预测补丁、执行日志、评估结果)被聚合为群体级经验池 S,所有子代智能体从中学习。
没有预设的能力目标。通过 Performance-Novelty 选择策略平衡即时性能与探索新颖性,系统持续发现新策略并纳入自身。
GEA 的三大核心组件:Archive → Parent Group Selection → Group Evolution
符号:𝒜。存储进化过程中发现的所有智能体。每个智能体 i 用任务成功向量 \(z_i \in \{0,1\}^D\) 表示,并关联性能分数 \(\alpha_i\)。其中 D 是探测任务集合的大小,每个维度表示智能体是否成功解决对应的探测任务。
其中 ε 是数值稳定性的小常数。距离越大表示两个智能体的能力分布越不同。
N_M(i) 是与智能体 i 余弦距离最小的 M 个智能体的集合。实验中 M=4。
性能作为主要选择标准,新颖性作为温和的偏差,实现利用与探索之间的平衡。
三阶段评估:健全性检查 (10 tasks) → Verified-Mini (50 tasks) → 完整基准 (仅 top-2)。30 次迭代,前 20 次用 Claude Haiku 4.5,后 10 次用 Claude Sonnet 4.5,反思全程用 GPT-o1。
跨多语言算法代码生成(C++、Rust、Java 等)。20 次迭代,前 10 次 Haiku 4.5,后 10 次 Sonnet 4.5。成功率超 40% 的智能体在 50 个未见任务上评估。
超参数:K = 2, M = 4 | 基线对比:DGM (60/40 次迭代) vs 人工设计 (OpenHands+GPT-5, Aider+GPT-5)
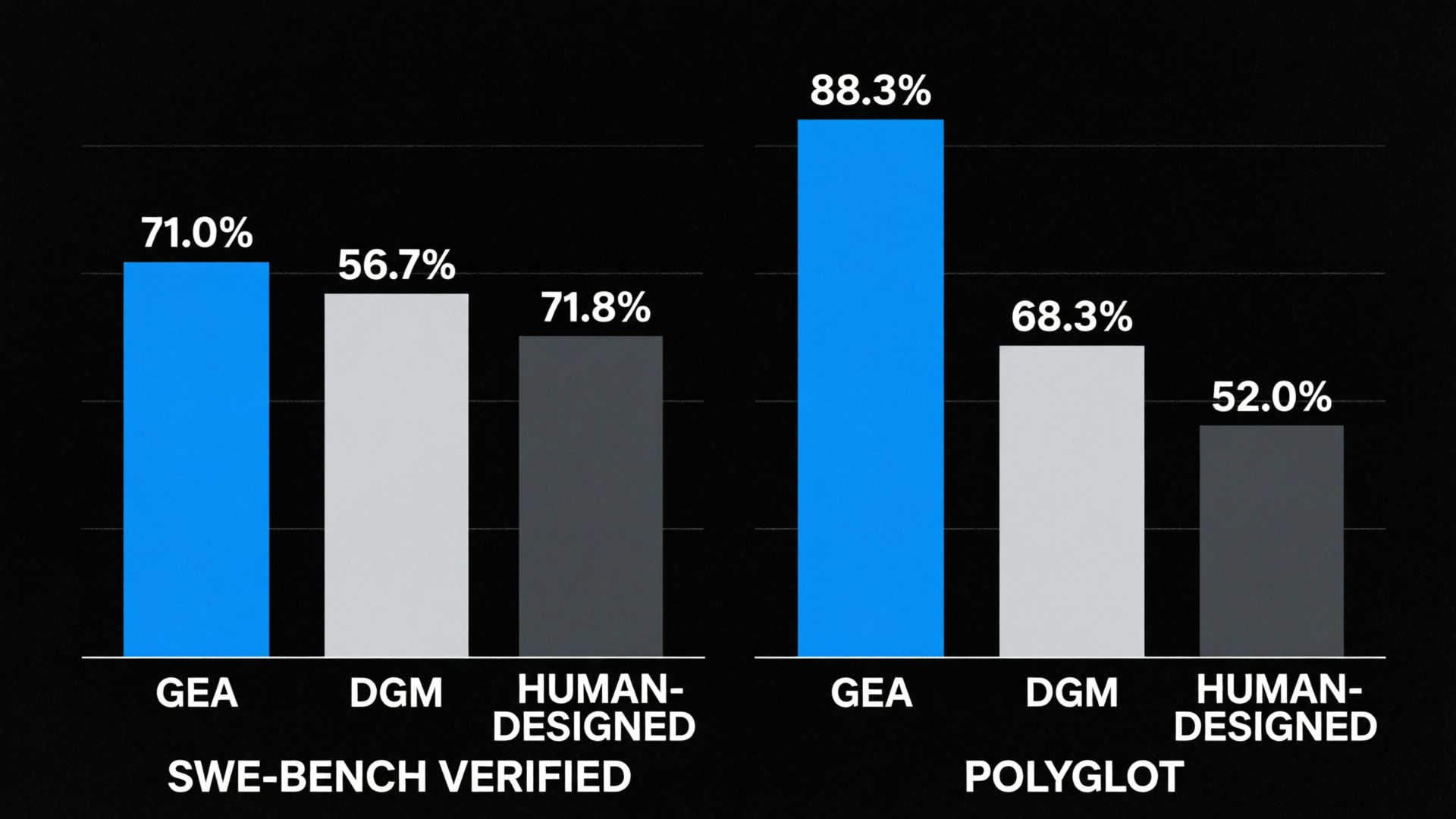
| 基准 | GEA | DGM | 人工设计 |
|---|---|---|---|
| SWE-bench Verified | 71.0% | 56.7% | 71.8% |
| Polyglot | 88.3% | 68.3% | 52.0% |
| 方法 | E1 | E2 | E3 | E4 | E5 | 平均 |
|---|---|---|---|---|---|---|
| DGM | 5 | 4 | 5 | 6 | 5 | 5.0 |
| GEA | 1 | 1 | 2 | 1 | 2 | 1.4 |
SWE-bench: ~$13,000/方法 | Polyglot: ~$1,500/方法。GEA 与 DGM 生成相同数量智能体,成本接近。
主要针对编码智能体的开放式自我改进。适用于需要智能体修改自身框架(工作流、工具使用、提示策略)的场景。
完整运行一次约需 $13,000 (SWE-bench) 或 $1,500 (Polyglot)。依赖 GPT-o1 与 Claude 4.5 系列模型。
开放式探索可能意外引入偏离人类目标的进化方向。补丁可能产生越来越复杂、难以完全理解的系统。